众所周知,Picasso是一个优秀的Android图片加载库。本篇并不讨论picasso的使用,而是来谈一谈picasso的缓存机制。
我们知道,目前主流的图片解决方案大部分都是三级缓存,即内存缓存、本地缓存和服务器缓存。这其中内存和本地缓存是在客户端实现的,picasso中也使用了这种方案。
Picasso的本地缓存我们在另外的篇幅中来谈,今天我们重点谈谈picasso的内存缓存。
在picasso源码下我们可以看到一个类——LruCache,这就是今天的主角,picasso的内存缓存就在这里实现的。
那么,为什么叫LruCache?
LRU是一种内存管理算法,是Least Recently Used的缩写。该算法的详细解释大家可以自行查阅。简单来说就是一个有序的集合,新添加的数据处于顶部,同时如果某个数据被访问,那么这个数据会被移至顶部;而当淘汰数据时,会从底部进行淘汰。如图:
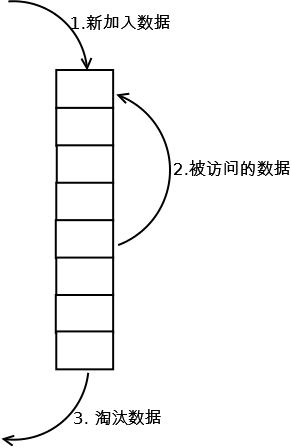
这个算法的核心思想是,如果一个数据近期被访问,那么被再次访问的可能性会远高于那些很久未被访问的数据,所以优先淘汰那些很久未被访问的数据。
了解了LRU算法,我们回过头再来看LruCache是如何实现这个思想的呢?
在LruCache源码中我们可以看到使用的是一个LinkedHashMap来进行数据存储的。LinkedHashMap是HashMap的子类,不同于HashMap之处在于它同时实现了双向链表,保证了数据的插入顺序,所以实际上最新插入的数据处于链表的尾部。而且LinkedHashMap可以用来实现LRU算法。怎么实现?我们来看看LruCache的构造函数
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("Max size must be positive.");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<String, Bitmap>(0, 0.75f, true);
}
if (maxSize <= 0) {
throw new IllegalArgumentException("Max size must be positive.");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<String, Bitmap>(0, 0.75f, true);
}
可以看到初始化LinkedHashMap时使用三个参数的构造函数
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
重点在accessOrder这个参数,当为false表示按插入顺序,当为true表示按访问顺序。LinkedHashMap内部通过重写get函数和内部类Entry的recordAccess方法来实现这部分逻辑,代码如下:
- public V get(Object key) {
- Entry<K,V> e = (Entry<K,V>)getEntry(key);
- if (e == null)
- return null;
- e.recordAccess(this);
- return e.value;
- }
- void recordAccess(HashMap<K,V> m) {
- LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
- if (lm.accessOrder) {
- lm.modCount++;
- remove();
- addBefore(lm.header);
- }
- }
可以看到如果调用get方法就会调用recordAccess方法。而在recordAccess中如果accessOrder为true,会从集合中将这个元素remove并插入到链表尾部。而且注意在HashMap的put方法中,当插入的元素已经存在,也同样会调用recordAccess方法,源码如下:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//将key-value添加到table[i]处
addEntry(hash, key, value, i);
return null;
}以上已经实现了访问排序,那么淘汰机制又是如何的呢?
在Picasso中使用了一个阀值来限制缓存的整体大小,在上面的构造函数中我们可以看到maxSize这个参数,这个就是缓存的最大阀值。如果我们没有自己定义这个阀值,那么picasso会使用一个默认大小,我们来看看LruCache的另外一个构造函数:
public LruCache(Context context) {
this(Utils.calculateMemoryCacheSize(context));
}
this(Utils.calculateMemoryCacheSize(context));
}
可以看到是通过Utils的相关函数计算出的默认阀值,通过源码我们来看看具体怎么得到的
static int calculateMemoryCacheSize(Context context) {
ActivityManager am = getService(context, ACTIVITY_SERVICE);
boolean largeHeap = (context.getApplicationInfo().flags & FLAG_LARGE_HEAP) != 0;
int memoryClass = am.getMemoryClass();
if (largeHeap && SDK_INT >= HONEYCOMB) {
memoryClass = ActivityManagerHoneycomb.getLargeMemoryClass(am);
}
// Target ~15% of the available heap.
return 1024 * 1024 * memoryClass / 7;
}
ActivityManager am = getService(context, ACTIVITY_SERVICE);
boolean largeHeap = (context.getApplicationInfo().flags & FLAG_LARGE_HEAP) != 0;
int memoryClass = am.getMemoryClass();
if (largeHeap && SDK_INT >= HONEYCOMB) {
memoryClass = ActivityManagerHoneycomb.getLargeMemoryClass(am);
}
// Target ~15% of the available heap.
return 1024 * 1024 * memoryClass / 7;
}
其中memoryClass是单个应用的最大内存限制,这个数值在不同的设备上是不一样的。
注意可以看到在HONEYCOME以上版本使用了不同的函数:getMemoryClass获取的是系统为应用分配的内存,不包含额外的补充;但是我们可以在manifest中将LargeHeap设为true来获取最大内存,而getLargeMemoryClass获取的就是这个补充后的内存大小。本篇就不详细展开了。
memoryClass的单位是MB,所以最后返回的阀值是应用最大内存的1/7,也就是说picasso的内存缓存最大会占用应用最大内存的15%左右。所以它不是一个固定值,而且因设备不同而不同的。
那么如何使用这个阀值来保证缓存空间大小的呢?我们来看看LruCache的set函数:
@Override public void set(String key, Bitmap bitmap) {
if (key == null || bitmap == null) {
throw new NullPointerException("key == null || bitmap == null");
}
Bitmap previous;
synchronized (this) {
putCount++;
size += Utils.getBitmapBytes(bitmap);
previous = map.put(key, bitmap);
if (previous != null) {
size -= Utils.getBitmapBytes(previous);
}
}
trimToSize(maxSize);
}
if (key == null || bitmap == null) {
throw new NullPointerException("key == null || bitmap == null");
}
Bitmap previous;
synchronized (this) {
putCount++;
size += Utils.getBitmapBytes(bitmap);
previous = map.put(key, bitmap);
if (previous != null) {
size -= Utils.getBitmapBytes(previous);
}
}
trimToSize(maxSize);
}
可以看到当set一个数据时,会增加缓存的当前大小,通过Utils.getBitmapBytes函数来获取图片大小并加至size参数上。
这里可以注意到,如果是已经存在的元素,则增加大小后还需要减去旧图片的大小,保证size的正确性。
最后会调用trimToSize函数,这个函数源码如下:
private void trimToSize(int maxSize) {
while (true) {
String key;
Bitmap value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(
getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize || map.isEmpty()) {
break;
}
Map.Entry<String, Bitmap> toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= Utils.getBitmapBytes(value);
evictionCount++;
}
}
}
while (true) {
String key;
Bitmap value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(
getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize || map.isEmpty()) {
break;
}
Map.Entry<String, Bitmap> toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= Utils.getBitmapBytes(value);
evictionCount++;
}
}
}
当缓存大小超过阀值,开始从头遍历map,清除图片缓存并改变缓存大小,直到缓存大小不再超过阀值。
因为在map中尾部的数据是最新的,而头部是最久未访问的,这样便实现了淘汰机制。
综上,我们剖析了picasso的内存缓存机制,它是在LinkedHashMap的基础上实现了LRU算法来进行内存管理,并且根据系统默认了一个合理的阀值,当缓存过大时会先清除久未使用的缓存。这样既加速了图片的加载,同时也保证了不过分消耗应用的内存。
这里要提一下Facebook开源的Fresco,同样作为图片加载解决方案,但是fresco使用了另外一种内存缓存——匿名共享内存。匿名共享内存实际上是在c/c++层创建使用的,所以不受Android虚拟机的内存限制,同时也不占用应用的最大内存。由于不少本篇内容,就简单介绍一下,有时间我会专门整理一篇文章来细说。
作者:chzphoenix 发表于2017/9/5 11:00:24 原文链接
阅读:192 评论:0 查看评论