Dagger2
Step1 使用
0x00 Dagger2介绍
Dagger is a fully static, compile-time dependency injection framework for both Java and Android. It is an adaptation of an earlier versioncreated by Square and now maintained by Google.
Dagger aims to address many of the development and performance issues that have plagued reflection-based solutions. More details can be found in this talk(slides) by +Gregory Kick.
Dagger2在Github主页上的自我介绍是:“A fast dependency injector for Android and Java“(一个提供给Android和Java使用的快速依赖注射器。)
Dagger2是由谷歌接手开发,最早的版本Dagger1 是由Square公司开发的。
0x000 依赖注入
0x01 Dagger2相较于Dagger1的优势是什么
0x02 依赖注入的好处
模块间解耦
就拿当前Android非常流行的开发模式MVP来说,使用Dagger2可以将MVP中的V 层与P层进一步解耦,这样便可以提高代码的健壮性和可维护性。
方便单元测试
0x03 配置
gradle 版本高于2.2的
dependencies {
compile 'com.google.dagger:dagger:2.x'
annotationProcessor 'com.google.dagger:dagger-compiler:2.x'
}
低于2.2的
apply plugin: 'com.neenbedankt.android-apt'
buildscript {
repositories {
jcenter()
}
dependencies {
classpath 'com.neenbedankt.gradle.plugins:android-apt:1.4'
}
}
dependencies {
apt 'com.google.dagger:dagger-compiler:2.0'
compile 'com.google.dagger:dagger:2.0'
}
将apply plugin和dependencies放在app的gradle里,把buildscript放在项目的gradle里即可
0x04 如何使用
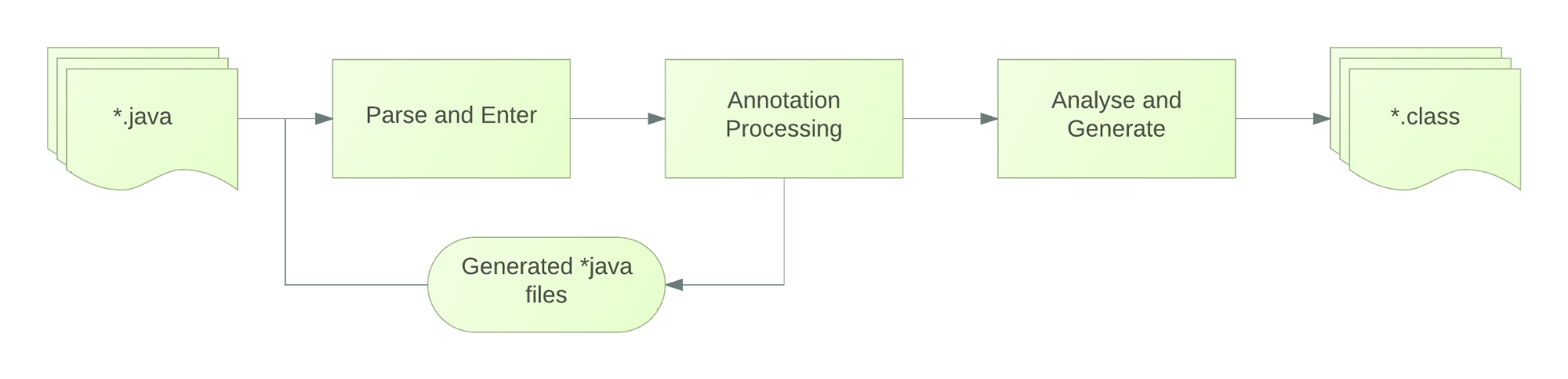
Dagger2通过注解来生成代码,有4(基础)+2(辅助)种不通过注解来定义不同的角色,主要的注解如下:
主要有两个作用,一个是使用在构造函数上,通过标记函数让Dagger2来使用(Dagger2通过Inject标记可以在需要这个类实例的时候来找到这个构造函数并把相关实例new出来)从而提供依赖,另一个作用就是标记在需要依赖的变量让Dagger2为其提供依赖,但要注意,成员变量要求是包级可见,也就是说@Inject不可以标记为private类型。
在Module中,我们定义的方法是用这个注解,以此来告诉Dagger我们想要构造对象并提供这些依赖。如果找不到被@Provides注释的方法提供对应参数对象的话,将会自动调用被@Inject注释的构造方法生成相应对象。即Provides注解的优先级要高于inject
Module类里面的方法专门提供依赖,所以我们定义一个类,用@Module注解,这样Dagger在构造类的实例的时候,就知道从哪里去找到需要的依赖。有的人可能有些疑惑,看了上面的@Inject,需要在构造函数上标记才能提供依赖,那么如果我们需要提供的类构造函数无法修改怎么办,比如一些jar包里的类,我们无法修改源码。这时候就需要使用Module了。Module可以给不能修改源码的类提供依赖,当然,能用Inject标注的通过Module也可以提供依赖
Component从根本上来说就是一个注入器,也可以说是@Inject和@Module的桥梁,被标注的Component的接口在编译时会产生相应的实例来作为依赖方和需要依赖方的桥梁,它的主要作用就是连接这两个部分。
这些标注看起来比较抽象,为了方便理解,用一张图来标注这4个注解之间的关系
![]()
左边的是依赖提供者,比如我们用Module标注的类或者用Injection标注的构造函数,右边的是依赖的需求方,例如我们用inject标注的变量,而Component则是连接两者的桥梁,Component从依赖提供者提供依赖,并把这些依赖注入相关的类中,Dagge正如其名,就像把匕首让依赖能够非常犀利的注入到需要它的地方。
Tips
这里需要说明一个问题,我们有两种方式可以提供依赖,一个是注解了@Inject的构造方法,一个是在Moudle里提供的依赖,Dagger2是按照如下规则选择依赖提供,规则如下:
步骤1:查找Module中是否存在创建该类的方法。
步骤2:若存在创建类方法,查看该方法是否存在参数
步骤2.1:若存在参数,则按从步骤1开始依次初始化每个参数
步骤2.2:若不存在参数,则直接初始化该类实例,一次依赖注入到此结束
步骤3:若不存在创建类方法,则查找Inject注解的构造函数,看构造函数是否存在参数
步骤3.1:若存在参数,则从步骤1开始依次初始化每个参数
步骤3.2:若不存在参数,则直接初始化该类实例,一次依赖注入到此结束
即从注解了@Inject的对象开始,从Module和注解过的构造方法中获得实例,若在获取该实例的过程中需要其他类的实例,则继续获取被需要类的实例对象的依赖,同样是从Module和标注过的构造方法中获取,并不断递归这个过程直到所有被需要的类的实例创建完成,在这个过程中Module的优先级高于注解过的构造方法。
在Moudle中根据返回类型来区分为谁提供依赖,当某个对象需要注入依赖时,Dagger2就会根据Moudle中标记了@Provide的方法的返回值来确定由谁为这个变量提供实例,那么问题来了,如果有两个一样的但会类型,该使用谁呢?这种场景称为依赖迷失,因此引入了@Qualifier来解决这个问题
- @Qualifier: 当类的类型不足以鉴别一个依赖的时候,我们就可以使用这个注解标示。例如:在Android中,我们会需要不同类型的context,所以我们就可以定义 qualifier注解“@perApp”和“@perActivity”,这样当注入一个context的时候,我们就可以告诉 Dagger我们想要哪种类型的context。
Scope的作用,提供局部单例的功能,局部范围是啥,那就是它注解的componnent的生命周期范围内。
我们知道@Singleton注解实际上实现的是一个全局单例模式,在实际开发中我们可能还需要一种局部单例的控件,比如说我们有三个Activity,MainActivity,BActivity和CActivity,我们想让MainActivity和BActivity共享同一个实例,而让CActivity获取另外一个实例,这又该怎么实现呢?在Dagger2中,我们可以通过自定义Scope来实现局部单例。
- @Scope: Dagger2可以通过自定义注解限定注解作用域,来管理每个对象实例的生命周期。
使用Scope需要注意以下几点
- component 的 inject 函数不要声明基类参数;
- Scope 注解必须用在 module 的 provide 方法上,否则并不能达到局部单例的效果;
- 如果 module 的 provide 方法使用了 scope 注解,那么 component 就必须使用同一个注解,否则编译会失败;
- 如果 module 的 provide 方法没有使用 scope 注解,那么 component 和 module 是否加注解都无关紧要,可以通过编译,但是没有局部单例效果;
- 对于直接使用 @Inject 构造函数的依赖,如果把 scope 注解放到它的类上,而不是构造函数上,就能达到局部单例的效果了;
0x06 简单的例子
通常要实现一个完整的依赖注入,需要有一下三个元素 Module、Component、Container
![]()
实现Moulde
@Module
public class MyModule{
@Provides
public B provideB(){
return new B();
}
}
实现Component
@Component(modules={ MyModule.class})
public interface MyComponent{
void inject(A a);
}
实现Container
A 就是可以被注入依赖关系的容器
public A{
@Inject
B b;
public void init(){
DaggerMyComponent.create().inject(this);
}
添加多个Moudle
一个Component可以添加多个Module,这样Component获取依赖时候会自动从多个Module中查找获取。添加多个Module有两种方法,一种是在Component的注解@Component(modules={××××,×××})中添加多个modules
@Component(modules={ModuleA.class,ModuleB.class,ModuleC.class})
public interface MyComponent{
...
}
或者使用@Moudle的include方法(includes={××××,×××})
@Module(includes={ModuleA.class,ModuleB.class,ModuleC.class})
public class MyModule{
...
}
@Component(modules={MyModule.class})
public interface MyComponent{
...
}
创建Moudle实例
DaggerMyComponent使用了Builder构造者模式。在构建的过程中,默认使用Module无参构造器产生实例。如果需要传入特定的Module实例,可以使用
DaggerMyComponent.builder()
.moduleA(new ModuleA())
.moduleB(new ModuleB())
.build()
@Name @Qualifier
区分返回类型相同,但是参数不同的构造器,通常与Provides方法结合在一起使用
@Qualifier @Documented
@Retention(RetentionPolicy.RUNTIME)
public @interface ContextLife {
String value() default "Application";
}
组件间依赖
假设ActivityComponent依赖ApplicationComponent,当使用ActivityComponent注入Container,如果找不到对应的依赖就会到ApplicaComponent中查找,前提是ApplicationComponent必须显式把ActivityComponent找不到的依赖提供给ActivityComponent。
单例的使用
创建某些对象有时候是耗时、浪费资源的或者需要确保其唯一性,这时就需要使用@Singleton注解标注为单例了。
Tips
在java中,单例通常保存在一个静态域中,这样的单例往往要等到虚拟机关闭时,该单例所占用的资源才释放,但是Dagger通过注解创建出来的单例并不保持在静态域上,而是在Component实例中,因此不同的Componet实例提供的对象是不同的
@Singleton就是一种Scope注解,也是Dagger2唯一自带的Scope注解
看例子中
SecondActivity 的 User 对象的地址和 MainActivity 中的 User 对象地址并不一样啊,这个单例好像失效了啊!事实上并不是这样,那么为什么这个单例“失效”了呢?两个 Activity 中的 Component 对象的地址是并不一样的,这样就好理解了 ——— 由于 Component 对象不是同一个,当然它们注入的对象也不会是同一个。那么我们如何解决这个问题呢?提供以下两个方案:
- 第一个,我们在 Application 层初始化 UserComponent,然后在 Activity 中直接获取这个 UserComponent 对象,由于 Application 在全局中只会初始化一次 -> 所以 Application 中的 UserComponent 对象只初始化一次 -> 我们每次在 Activity 中获取 Application 中的这个 UserComponent 当然就是同一个了
- 第二个,我们将 UserComponent 改成抽象类,然后使用单例模式,这样每次 Activity 中获取的 Component 不也是同一个么
使用过程中需要注意——两个拥有依赖关系的 Component 是不能有相同 @Scope 注解的!
可以使用@Subcomponent注解拓展原有component。Subcomponent其功能效果优点类似component的dependencies。但是使用@Subcomponent不需要在父component中显式添加子component需要用到的对象,只需要添加返回子Component的方法即可,子Component能自动在父Component中查找缺失的依赖。
@Component(modules=××××) public AppComponent{
SubComponent subComponent ();
}
@Subcomponent(modules=××××) public SubComponent{
void inject(SomeActivity activity);
}
public class SomeActivity extends Activity{
public void onCreate(Bundle savedInstanceState){
App.getComponent().subCpmponent().inject(this);
}
}
Tips
@Subcomponent 和 @Component 的实际使用场景定义
Component 依赖
你想让两个 Component 都独立,没有任何关联. 你想很明确的告诉别人我这个 Component 所依赖的 Component.
Subcomponent 依赖
你想让两个 Component 内聚. 你应该并不关心这个 Component 依赖哪个 Component.
Step2 原理分析
依赖注入,我们知道,它本质上就是采用某种工厂模式去创建实例,并为目标类提供实例
连接器Component
- 通过Component.Builder创建component、Builder传入component依赖的moudle
- Component初始化 为Moudle中的每一个实例创建Provider
- 为Provider生成对应的工厂方法
- 重载component接口中方法,通过调用Provider
提供者Provider
Moulde中的每个@provider都会自动生成一个Provider相对应的类,结构如下,核心是get方法,在其实现类中,重载get并返回实例
public interface Provider<T> {
T get();
}
工厂生产者Factory
在Moudle中,提供了实例的创建方法,在Dagger2生成的源码中,所有的实例都会生成对应的Factory,注入的时候都是通过Factory来创建实例,本质上还是调用了Moudle中的provider方法。
成员注入器 MembersInjector
在DaggerTasksComponent,已经生成有Provider tasksPresenterProvider; 为了实现注入,还生成了一个注入器 MembersInjector tasksActivityMembersInjector;这个注入器的作用就是往TasksActivity注入@Inject声明的东西,这里只有mTasksPresenter需要注入。
注入器结构如下
public interface MembersInjector<T> {
void injectMembers(T instance);
}
查看DaggerTasksComponent源码可以看出
- 注入都是通过注入器实现的
- 植入是发生在调用inject的时候的
Field injection
- 如何注入
拥有Fields injection行为的类A,Dagger会为它生成一个注入器A_MembersInjector;
注入器的结构如下:
public interface MembersInjector<T> {
void injectMembers(T instance);
}
注入器A_MembersInjector需要实现方法:injectMembers(T instance),该方法通过Provider注入具体的实例
- 何时注入
注入时机有两个
- 当对应的A_Factory中的get() 方法被调用的时候;
- 主动调用Component中定义的inject()方法时
Scope
Scope是一种作用域的描述,真正要表达的是类、Component、Module一体的关系。本质上依赖于component的生命周期的
Qualifier
@Qualifier就是一个tag。想象一下,如果在Module中你需要provide两个TasksDataSource,你就需要通过@Qualifier来区分了。
实际上,在Dagger2自动生成的代码中,它会对Qualifier标识的方法生成不同的工厂类,如上就分别对应TasksRepositoryModule_ProvideTasksRemoteDataSourceFactory
和
TasksRepositoryModule_ProvideTasksLocalDataSourceFactory,最终在引用的时候,就分别通过这两个工厂类提供实例。
参考链接
作者:XSF50717 发表于2017/7/29 16:20:16
原文链接